
Is topic modelling obsolete?


It wasn’t so long ago that topic modelling was all the rage, particularly in the digital humanities. Techniques like Latent Dirichlet Allocation (LDA), which can be used to unveil the hidden thematic structures within documents, extended the possibilities of distant reading—rather than manually coding themes or relying solely on close reading (which brings limits in scale), scholars could now infer latent topics from large corpora.
What is it for? Topic modeling gives us a way to infer the latent structure behind a collection of documents. In principle, it could work at any scale, but I tend to think human beings are already pretty good at inferring the latent structure in (say) a single writer’s oeuvre. I suspect this technique becomes more useful as we move toward a scale that is too large to fit into human memory.
Topic modelling was a significant breakthrough for text and cultural analytics: unsupervised, scalable, and—at least in theory—interpretable. One of the more famous illustrations of its utility is a set of topics drawn from an analysis of 1.8 million articles from The New York Times.
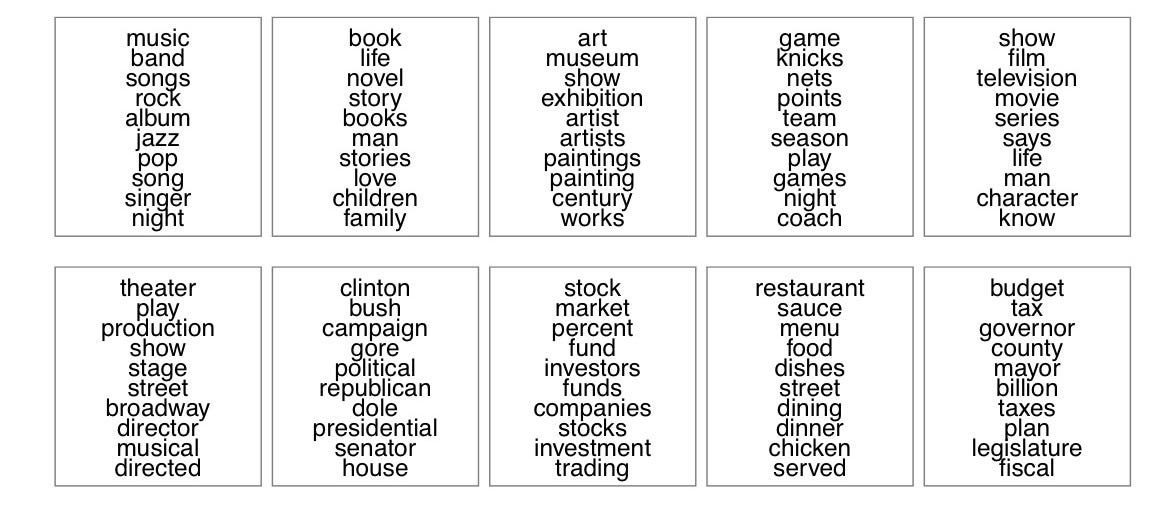
A good topic model lays the thematic structures of a corpus bare, allowing researchers to discern the dominant concerns, recurring motifs, and conceptual fault lines that shape a body of texts (without having to close read the 1.8 million texts).
Researchers in the humanities and social sciences have used topic modelling to explore matters like disciplinary history, literary interviews, refugee policies, public medical discourse, and journalistic sources.
But things have changed. When large language models (LLMs) can summarise a thousand documents in the blink of an eye, why bother clustering them into topics? It’s tempting to declare topic modelling obsolete, a relic of the pre-transformer age.
But that may be a mistake.
Topic modelling in its classical form, most famously represented by LDA, works by treating documents as ‘bags of words’. It ignores word order and syntax, instead relying on the statistical distribution of terms to infer a set of hidden topics that might explain the composition of the corpus. Each document is assumed to be a mixture of topics, and each topic a mixture of words (ps. Ted Underwood’s ‘just simple enough’ explanation remains one of the most intuitive out there). This probabilistic model is mathematically elegant and, in the right hands (they are dangerously easy to misapply and misinterpret), surprisingly useful to researchers in the humanities and social sciences.
Topic modelling has its limitations. It struggles with short texts, where the lack of word variety makes it difficult to infer meaningful themes. It often produces incoherent or ambiguous topics when vocabularies overlap too heavily, blurring the boundaries between distinct discourses. And it completely ignores context, treating words as interchangeable tokens rather than meaning-laden expressions situated in syntax and discourse. Such issues aren’t unique to topic modelling, they are endemic to the broader practice of distant reading. Any attempt to abstract patterns from large-scale textual data risks flattening nuance, effacing ambiguity, and mistaking correlation for significance. The very promise of distant reading—to grasp the shape of meaning at scale—comes with the peril of overlooking the grain of the text (and while that still upsets some of our colleagues, distant readers are fine with that).
Enter the transformers.
In recent years, contextual embeddings have revolutionised how we represent and analyse language. Instead of reducing a sentence to a flat list of word counts, models like SBERT embed entire phrases, paragraphs, or documents as dense vectors in high-dimensional space, with semantic similarity encoded directly into the geometry of that space.
This changes everything. With vector embeddings, clustering documents no longer requires tallying co-occurrences of tokens. Instead, one can compare meanings. Sentences about ‘green energy subsidies’ and ‘carbon border adjustments’ may not share vocabulary, but they occupy neighbouring regions in vector space. The upshot is that modern clustering methods, using embeddings as input, can group documents in ways that are far more aligned with human intuition.
To make matters more dramatic, large language models like GPT-4 can now take the clusters these embeddings generate and supply plain-English summaries or topic labels on demand. Where researchers once agonised over whether a given cluster of words was best labelled ‘immigration’ or ‘border policy’, we can now feed representative passages into a model and let it suggest a label (and it does a surprisingly good job at this).
This is not so much a death as a metamorphosis. The term ‘topic modelling’ may still conjure up images of LDA’s clunky output—lists of keywords like ‘economy, market, growth, price, trade’—but in practice, the field has moved on. Newer approaches like BERTopic, developed by Maarten Grootendorst and now widely adopted, combine transformer embeddings with clustering algorithms such as HDBSCAN and UMAP for dimensionality reduction. These tools allow researchers to automatically identify clusters of related documents and label them using a hybrid of statistical and semantic techniques.
Rather than abandoning the idea of unsupervised topic discovery, modern practitioners are enhancing it with deeper language understanding. Instead of relying solely on statistical co-occurrence, they are exploiting the rich semantic maps created by LLMs.
A typical modern pipeline might proceed as follows. First, the documents are embedded using a transformer-based model, producing high-dimensional vectors that capture their semantic content. These vectors are then reduced to more manageable dimensions using UMAP, allowing for more efficient analysis and visualisation. Clustering is performed using HDBSCAN, a density-based algorithm that automatically identifies the optimal number of clusters without forcing every document into a group. Finally, each cluster is labelled by prompting a language model with representative excerpts and asking it to generate a short, coherent description of the underlying theme.
The result is a system that not only finds topics, but explains them.
In many respects, this new approach is superior. It is more sensitive to context, more flexible, and more accurate in reflecting how humans actually distinguish themes. It also opens the door to multilingual topic modelling, multimodal applications, and iterative refinement of labels using natural language interaction.
But something has also been lost. The statistical transparency of LDA, with its interpretable Dirichlet priors and clearly defined parameters, has given way to a more opaque process. Embeddings are hard to explain. LLMs, while powerful, are notoriously prone to hallucination. And while the outputs may appear coherent, it’s often difficult to say exactly why a model assigned a particular theme to a given cluster. For applications where explainability is paramount, this can be a real problem.
And then there is the matter of infrastructure. Classical topic models could be trained on a laptop; embedding-based approaches and LLM-assisted pipelines often require access to GPUs, APIs, or paid compute resources.
So, is topic modelling obsolete? If by ‘topic modelling’ one means LDA-as-default (that is, the routine application of bag-of-words models with fixed priors and hand-tuned parameters), then yes, it is increasingly difficult to justify. For cases involving nuanced language, short texts, or diverse corpora, newer approaches consistently outperform it in both coherence and interpretability.
But if we mean topic modelling in the broader sense—the attempt to discover latent thematic structures in texts, without human supervision—then the answer is an emphatic no. We no longer need to rely exclusively on sparse counts and Bayesian inference, and can also turn to semantic embeddings, density-based clustering, and large language models capable of summarising and labelling clusters.
Still, that’s not to say the old ways no longer yield insight. Classical LDA, for all its limitations, remains a transparent, lightweight, and often surprisingly effective tool, especially in large-scale, resource-constrained, or pedagogical settings. Its (relative) mathematical ‘simplicity’ can be a virtue, and in some contexts, its limitations are precisely what make it interpretable and auditable.
The increasingly baroque nature of modern topic pipelines—embedding models, manifold reduction, density-based clustering, LLM-based labelling—can introduce a type of methodological overengineering. It becomes possible to generate beautifully coherent topic clusters that are, in effect, artefacts of your pipeline rather than reflections of the corpus. At that point, topic modelling risks becoming a performance, not an inquiry.
Great read. I'm currently working on a crisis informatics project utilizing BERTopic. I have seen the "beautifully coherent" but useless topics you describe at the end of the article. Looking at general-purpose and domain-specific (crisis texts) encoders yielded some interesting results.
The domain-specific encoder yielded clusters with lower standard topic metrics (NPMI/Coherence) but better represented actionable intelligence and themes of a given crisis. Some care needs to go into how these new topic models are evaluated. In our case, developing an "actionability" score using human and LLM judges better reflected what themes were useful when extracted from the corpus. Modern LLMs struggle to cluster themes at-scale but can serve as a good judge of topics extracted using LDA/BERTopic.